[GitHub (source code for all languages)](https://github.com/zserge/tinylangs), also linked above. - [Assembly](https://zserge.com/posts/langs-asm/) - [BASIC](https://zserge.com/posts/langs-basic/) - [Forth/MOUSE](https://zserge.com/posts/langs-mouse/) - [Lisp](https://zserge.com/posts/langs-lisp/) - [APL/K](https://zserge.com/posts/langs-apl/) - [PL/0](https://zserge.com/posts/langs-pl0/) The GitHub says "50 lines of code" but the largest example is 74 lines excluding whitespace and comments.
 adam-mcdaniel.github.io
adam-mcdaniel.github.io
> Dune is a shell designed for powerful scripting. Think of it as an unholy combination of `bash` and **Lisp**. > > You can do all the normal shell operations like piping, file redirection, and running programs. But, you also have access to a standard library and functional programming abstractions for various programming and sysadmin tasks! > > 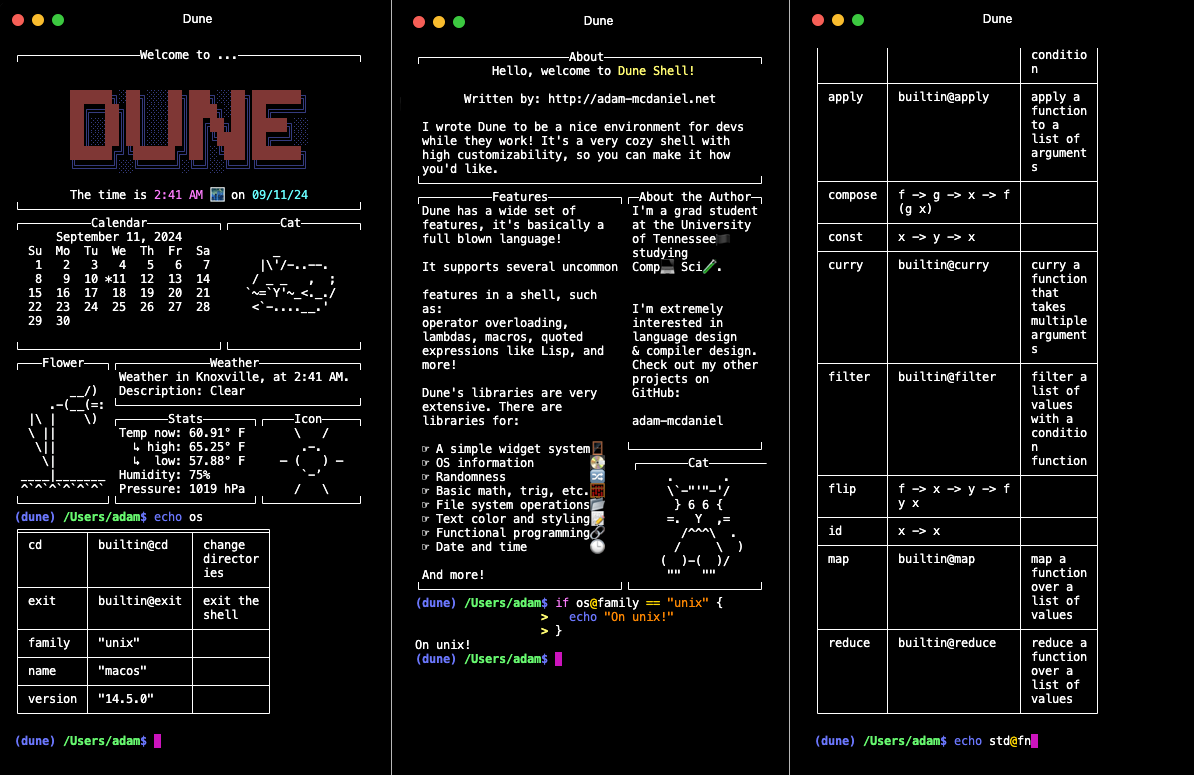
> Fennel is a programming language that brings together the simplicity, speed, and reach of [Lua](https://www.lua.org) with the flexibility of a [lisp syntax and macro system.](https://en.wikipedia.org/wiki/Lisp_(programming_language)) > > - **Full Lua compatibility:** Easily call any Lua function or library from Fennel and vice-versa. > - **Zero overhead:** Compiled code should be just as efficient as hand-written Lua. > - **Compile-time macros:** Ship compiled code with no runtime dependency on Fennel. > - **Embeddable:** Fennel is a one-file library as well as an executable. Embed it in other programs to support runtime extensibility and interactive development. > > Anywhere you can run Lua code, you can run Fennel code. Example: > ```lisp > ;; Sample: read the state of the keyboard and move the player accordingly > (local dirs {:up [0 -1] :down [0 1] :left [-1 0] :right [1 0]}) > > (each [key [dx dy] (pairs dirs)] > (when (love.keyboard.isDown key) > (let [[px py] player > x (+ px (* dx player.speed dt)) > y (+ py (* dy player.speed dt))] > (world:move player x y)))) > ```
 dl.acm.org
dl.acm.org
Abstract: > We say that an imperative data structure is *snapshottable* or *supports snapshots* if we can efficiently capture its current state, and restore a previously captured state to become the current state again. This is useful, for example, to implement backtracking search processes that update the data structure during search. > > Inspired by a data structure proposed in 1978 by Baker, we present a *snapshottable store*, a bag of mutable references that supports snapshots. Instead of capturing and restoring an array, we can capture an arbitrary set of references (of any type) and restore all of them at once. This snapshottable store can be used as a building block to support snapshots for arbitrary data structures, by simply replacing all mutable references in the data structure by our store references. We present use-cases of a snapshottable store when implementing type-checkers and automated theorem provers. > > Our implementation is designed to provide a very low overhead over normal references, in the common case where the capture/restore operations are infrequent. Read and write in store references are essentially as fast as in plain references in most situations, thanks to a key optimisation we call *record elision*. In comparison, the common approach of replacing references by integer indices into a persistent map incurs a logarithmic overhead on reads and writes, and sophisticated algorithms typically impose much larger constant factors. > > The implementation, which is inspired by Baker's and the OCaml implementation of persistent arrays by Conchon and Filliâtre, is both fairly short and very hard to understand: it relies on shared mutable state in subtle ways. We provide a mechanized proof of correctness of its core using the Iris framework for the Coq proof assistant.
 github.com
github.com
Back from break, I'm going to start posting regularly again. This is an interesting node-based visual programming environment with very cool graphics. It's written on Clojure but the various "cards" (nodes) can include SQL, R, DALL-E API calls, or anything else. > 

 github.com
github.com
Excerpt: > This is a reconstruction -- extracted and very lightly edited -- of the "prehistory" of Rust development, when it was a personal project between 2006-2009 and, after late 2009, a Mozilla project conducted in private. > > The purposes of publishing this now are: > > - It might encourage someone with a hobby project to persevere > - It might be of interest to language or CS researchers someday > - It might settle some arguments / disputed historical claims Rust started being developed 18 years ago. This is how it looked until 14 years ago, where I believe the rest of development is on [rust-lang/rust](https://github.com/rust-lang/rust/commits/c2d4c1116f96463b8af222365d61d05bc42a78ac/?after=c2d4c1116f96463b8af222365d61d05bc42a78ac+34). The [first Rust program](https://github.com/graydon/rust-prehistory/blob/b0fd440798ab3cfb05c60a1a1bd2894e1618479e/test/foo.rs) looks completely different than the Rust we know today.
 firedancer-lang.com
firedancer-lang.com
[GitHub](https://github.com/fal-works/firedancer) > Haxe-based language for defining 2D shmups bullet-hell patterns. The [VM](https://github.com/fal-works/firedancer-vm) also runs in [Haxe](https://haxe.org/).
 blog.sigplan.org
blog.sigplan.org
> Soundly handling linearity requires special care in the presence of effect handlers, as the programmer may inadvertently compromise the integrity of a linear resource. For instance, duplicating a continuation that closes over a resource can lead to the internal state of the resource being corrupted or discarding the continuation can lead to resource leakage. Thus a naïve combination of linear resources and effect handlers yields an unsound system. ... > In the remainder of this blog post we describe a novel approach to rule out such soundness bugs by tracking *control-flow linearity*, a means to statically assure how often a continuation may be invoked which mediates between linear resources and effectful operations in order to ensure that effect handlers cannot violate linearity constraints on resources. We focus on our implementation in **Links**. The full technical details are available in our open access POPL'24 distinguished paper [Soundly Handling Linearity](https://dl.acm.org/doi/10.1145/3632896).
> Programming models like the Actor model and the Tuplespace model make great strides toward simplifying programs that communicate. However, a few key difficulties remain. > > The Syndicated Actor model addresses these difficulties. It is closely related to both Actors and Tuplespaces, but builds on a different underlying primitive: *eventually-consistent replication of state* among actors. Its design also draws on widely deployed but informal ideas like publish/subscribe messaging. For reference, [actors](https://en.wikipedia.org/wiki/Actor_model) and [tuple-spaces](https://en.m.wikipedia.org/wiki/Tuple_space) are means to implement concurrent programs. **Actors** are essentially tiny programs/processes that send (push) messages to each other, while a **tuple-space** is a shared repository of data ("tuples") that can be accessed (pulled) by different processes (e.g. actors). ... > A handful of Domain-Specific Language (DSL) constructs, together dubbed *Syndicate*, expose the primitives of the Syndicated Actor model, the features of dataspaces, and the concepts of conversational concurrency to the programmer in an ergonomic way. ... > To give some of the flavour of working with Syndicate DSL constructs, here's a program written in [JavaScript extended with Syndicate constructs](https://syndicate-lang.org/code/js/): > > ```javascript > function chat(initialNickname, sharedDataspace, stdin) { > spawn 'chat-client' { > field nickName = initialNickname; > > at sharedDataspace assert Present(this.nickname); > during sharedDataspace asserted Present($who) { > on start console.log(`${who} arrived`); > on stop console.log(`${who} left`); > on sharedDataspace message Says(who, $what) { > console.log(`${who}: ${what}`); > } > } > > on stdin message Line($text) { > if (text.startsWith('/nick ')) { > this.nickname = text.slice(6); > } else { > send sharedDataspace message Says(this.nickname, text); > } > } > } > } > ``` [Documentation](https://syndicate-lang.org/doc/) [Comparison with other programming models](https://syndicate-lang.org/about/syndicate-in-context/) [History](https://syndicate-lang.org/about/history/) [Author's thesis](https://syndicate-lang.org/papers/conversational-concurrency-201712310922.pdf)
Even though it's very unlikely to become popular (and if so, [it will probably take a while](https://en.wikipedia.org/wiki/Timeline_of_programming_languages)), there's a lot you learn from creating a programming language that applies to other areas of software development. Plus, it's fun!
armchair_progamer 1 month ago • 100%
The Tetris design system:
Write code, delete most of it, write more code, delete more of it, repeat until you have a towering abomination, ship to client.
The blog post is the author's impressions of Gleam after [it released version 1.4.0](https://gleam.run/news/supercharged-labels/). [Gleam](https://gleam.run/) is an upcoming language that is getting a lot of highly-ranked articles. It runs on the [Erlang virtual machine (BEAM)](https://en.wikipedia.org/wiki/BEAM_(Erlang_virtual_machine)), making it great for distributed programs and a competitor to [Elixir](https://elixir-lang.org/) and [Erlang (the language)](https://www.erlang.org/). It also compiles to [JavaScript](https://www.javascript.com/), making it a competitor to [TypeScript](https://www.typescriptlang.org/). But unlike Elixir, Erlang, and TypeScript, it's *strongly* typed (not just gradually typed). It has "functional" concepts like algebraic data types, immutable values, and first-class functions. The syntax is modeled after [Rust](https://www.rust-lang.org/) and its [tutorial](https://tour.gleam.run/) is modeled after [Go's](https://go.dev/tour/). Lastly, it has a very large community.
> Zyme is an [esoteric](https://en.wikipedia.org/wiki/Esoteric_programming_language) language for [genetic programming](https://en.wikipedia.org/wiki/Genetic_programming): creating computer programs by means of natural selection. > > For successful evolution mutations must generate a wide range of phenotypic variation, a feat nearly impossible when randomly modifying the code of conventional programming languages. Zyme is designed to maximize the likelihood of a bytecode mutation creating a novel yet non-fatal change in program behavior. > > Diverging from conventional register or stack-based architectures, Zyme uses a unique molecular automaton-based virtual machine, mimicking an abstract cellular metabolism. This design enables fuzzy control flow and precludes invalid runtime states, transforming potential crashes into opportunities for adaptation. Very unique, even for an esoteric language. Imagine a program that gets put through natural selection and "evolves" like a species: the program is cloned many times, each clone is slightly mutated, the clones that don't perform as well on some metric are discarded, and the process is repeated; until eventually you have programs that do great on the metric, that you didn't write.
 www.cs.cornell.edu
www.cs.cornell.edu
Key excerpt: > At [OOPSLA 2020](https://2020.splashcon.org/track/splash-2020-oopsla), [Prof. Dietrich Geisler](https://www.cs.cornell.edu/~dgeisler/) published [a paper](https://dl.acm.org/doi/10.1145/3428241) about geometry bugs and a type system that can catch them. The idea hasn't exactly taken over the world, and I wish it would. The paper's core insight is that, to do a good job with this kind of type system, you need your types to encode three pieces of information: > > - the reference frame (like model, world, or view space) > - the coordinate scheme (like Cartesian, homogeneous, or polar coordinates) > - the geometric object (like positions and directions) > > In Dietrich's language, these types are spelled `scheme<frame>.object`. Dietrich implemented these types in a language called [Gator](https://github.com/cucapra/gator) with help from [Irene Yoon](https://www.cis.upenn.edu/~euisuny/), [Aditi Kabra](https://aditink.github.io), [Horace He](https://horace.io), and Yinnon Sanders. With a few helper functions, you can get Gator to help you catch all the geometric pitfalls we saw in this post.
Abstract: > File formats specify how data is encoded for persistent storage. They cannot be formalized as context-free grammars since their specifications include context-sensitive patterns such as the random access pattern and the type-length-value pattern. We propose a new grammar mechanism called Interval Parsing Grammars IPGs) for file format specifications. An IPG attaches to every nonterminal/terminal an interval, which specifies the range of input the nonterminal/terminal consumes. By connecting intervals and attributes, the context-sensitive patterns in file formats can be well handled. In this paper, we formalize IPGs' syntax as well as its semantics, and its semantics naturally leads to a parser generator that generates a recursive-descent parser from an IPG. In general, IPGs are declarative, modular, and enable termination checking. We have used IPGs to specify a number of file formats including ZIP, ELF, GIF, PE, and part of PDF; we have also evaluated the performance of the generated parsers.
armchair_progamer 1 month ago • 99%
But is it rewritten in Rust?
armchair_progamer 1 month ago • 100%
C++

 www.cs.cornell.edu
www.cs.cornell.edu
> I created [Bril](https://capra.cs.cornell.edu/bril/), the Big Red Intermediate Language, to support the class's implementation projects. Bril isn't very interesting from a compiler engineering perspective, but I think it's pretty good for the specific use case of teaching compilers classes. Here's a factorial program: > > ```ruby > @main(input: int) { > res: int = call @fact input; > print res; > } > > @fact(n: int): int { > one: int = const 1; > cond: bool = le n one; > br cond .then .else; > .then: > ret one; > .else: > decr: int = sub n one; > rec: int = call @fact decr; > prod: int = mul n rec; > ret prod; > } > > ``` > > Bril is the only compiler IL I know of that is specifically designed for education. Focusing on teaching means that Bril prioritizes these goals: > > - It is fast to get started working with the IL. > - It is easy to mix and match components that work with the IL, including things that fellow students write. > - The semantics are simple, without too many distractions. > - The syntax is ruthlessly regular. > > Bril is different from other ILs because it prioritizes those goals above other, more typical ones: code size, compiler speed, and performance of the generated code. > > Aside from that inversion of priorities, Bril looks a lot like any other modern compiler IL. It's an instruction-based, assembly-like, typed, [ANF](https://en.wikipedia.org/wiki/A-normal_form) language. There's a quote from [why the lucky stiff](https://en.wikipedia.org/wiki/Why_the_lucky_stiff) where he introduces [Camping](https://camping.github.io/camping.io/), the original web microframework, as "a little white blood cell in the vein of Rails." If LLVM is an entire circulatory system, Bril is a single blood cell. [Reference](https://capra.cs.cornell.edu/bril/) [GitHub](https://github.com/sampsyo/bril)
 glisp.app
glisp.app
[GitHub](https://github.com/baku89/glisp) > Glisp is a Lisp-based design tool that combines generative approaches with traditional design methods, empowering artists to discover new forms of expression. > Glisp literally uses a customized dialect of Lisp as a project file. As the [Code as Data](https://en.wikipedia.org/wiki/Code_as_data) concept of Lisp, the project file itself is the program to generate an output at the same time as a tree structure representing SVG-like list of shapes. And even the large part of the app's built-in features are implemented by the identical syntax to project files. By this nature so-called [homoiconicity](https://en.wikipedia.org/wiki/Homoiconicity), artists can dramatically hack the app and transform it into any tool which can be specialized in various realms of graphics -- daily graphic design, illustration, generative art, drawing flow-chart, or whatever they want. I call such a design concept "purpose-agnostic". Compared to the most of existing design tools that are strictly optimized for a concrete genre of graphics such as printing or UI of smartphone apps, I believe the attitude that developers intentionally keep being agnostic on how a tool should be used by designers makes it further powerful.
Intro: > CF Bolz-Tereick wrote some excellent posts in which they [introduce a small IR and optimizer](https://pypy.org/posts/2022/07/toy-optimizer.html) and [extend it with allocation removal](https://pypy.org/posts/2022/10/toy-optimizer-allocation-removal.html). We also did a live stream together in which we did [some more heap optimizations](https://www.youtube.com/watch?v=w-UHg0yOPSE). > > In this blog post, I'm going to write a small abtract interpreter for the Toy IR and then show how we can use it to do some simple optimizations. It assumes that you are familiar with the little IR, which I have reproduced unchanged in [a GitHub Gist](https://gist.github.com/tekknolagi/4425b28d5267e7bae8b0d7ef8fb4a671). > > Abstract interpretation is a general framework for efficiently computing properties that must be true for all possible executions of a program. It's a widely used approach both in compiler optimizations as well as offline static analysis for finding bugs. I'm writing this post to pave the way for CF's next post on proving abstract interpreters correct for range analysis and known bits analysis inside PyPy. [Abstract Interpretation in a Nutshell](https://www.di.ens.fr/~cousot/AI/IntroAbsInt.html)
This blog post explains why [**algebraic data types**](http://wiki.haskell.org/Algebraic_data_type) are "algebraic" - how every algebraic data type corresponds to a mathematical equation - and describes some ways to use a type's corresponding equation to reason about the type itself.
 arxiv.org
arxiv.org
Abstract: > We propose a novel type system for effects and handlers using modal types. Conventional effect systems attach effects to function types, which can lead to verbose effect-polymorphic types, especially for higher-order functions. Our modal effect system provides succinct types for higher-order first-class functions without losing modularity and reusability. The core idea is to decouple effects from function types and instead to track effects through *relative* and *absolute* modalities, which represent transformations on the ambient effects provided by the context. > > We formalise the idea of modal effect types in a multimodal System F-style core calculus `Met` with effects and handlers. `Met` supports modular effectful programming via modalities without relying on effect variables. We encode a practical fragment of a conventional row-based effect system with effect polymorphism, which captures most common use-cases, into `Met` in order to formally demonstrate the expressive power of modal effect types. To recover the full power of conventional effect systems beyond this fragment, we seamlessly extend `Met` to `Mete` with effect variables. We propose a surface language `Metel` for `Mete` with a sound and complete type inference algorithm inspired by `FreezeML`. **Modal logic** and **modal types** have also been used to implement [Rust-like "ownership"](https://arxiv.org/pdf/2310.18166), [staged metaprogramming](https://arxiv.org/abs/2111.08099), [distributed programming](https://www.cs.princeton.edu/~dpw/papers/modal-proofs-as-programs-short.pdf), and more.
armchair_progamer 2 months ago • 100%
“I’ve got 10 years of googling experience”.
“Sorry, we only accept candidates with 12 years of googling experience”.
armchair_progamer 2 months ago • 100%
[**IELR(1)**](https://dl.acm.org/doi/10.1016/j.scico.2009.08.001) a niche [LR(1)](https://en.wikipedia.org/wiki/LR_parser) parser generator. More well-known are [**LALR**](https://en.wikipedia.org/wiki/LALR_parser) and [**Pager's "minimal" LR(1) algorithm (PGM(1))**](https://doi.org/10.1007/BF00290336), but IELR(1) can generate a parser for certain grammars that those cannot. [This post by the same authors](https://branchtaken.com/blog/2022/05/09/art-of-the-state.html) goes into more detail about the problem IELR(1) solves. The linked post is about implementing IELR(1), in particular the challenges the authors faced doing so. They've implemented IERL(1) in their own parser generator, [`hocc`](https://branchtaken.com/blog/2022/02/20/hardly-original-compiler-compiler.html), that they're writing for their own language, [Hemlock](https://github.com/BranchTaken/Hemlock): "a systems programming language that emphasizes reliable high performance parallel computation" that is (or at least very similar to) an [ML](https://en.wikipedia.org/wiki/ML_(programming_language)) dialect.
 github.com
github.com
> Bio is an experimental Lisp dialect similar to Scheme, with an interpreter written in [Zig](https://ziglang.org) > > Features include macros, garbage collection, error handling, a module facility, destructuring, and a standard library. > > Example: > > ```lisp > (filter > (quicksort '(5 40 1 -3 2) <) > (λ (x) (>= x 0))) > > (1 2 5 40) > ```
> Most visual programming environments fail to get any usage. Why? They try to replace code syntax and business logic but developers never try to visualize that. Instead, developers visualize state transitions, memory layouts, or network requests. > > In my opinion, those working on visual programming would be more likely to succeed if they started with aspects of software that developers already visualize. ... > Developers say they want "visual programming", which makes you think "oh, let's replace `if` and `for`". But nobody ever made a flow chart to read `for (i in 0..10) if even?(i) print(i)`. Developers familiar with code already like and understand textual representations to read and write business logic[^2^](https://blog.sbensu.com/posts/demand-for-visual-programming/#fn-2). > > **Let's observe what developers *do*, not what they *say*.** > > Developers do spend the time to visualize aspects of their code but rarely the logic itself. They visualize other aspects of their software that are *important, implicit, and hard to understand*. > > Here are some visualizations that I encounter often in [serious contexts of use](https://notes.andymatuschak.org/z7vdiuQK7HuFyi4V5EemF3e): > > - Various ways to visualize the codebase overall. > - Diagrams that show how computers are connected in a network > - Diagrams that show how data is laid out in memory > - Transition diagrams for state machines. > - Swimlane diagrams for request / response protocols. > > *This* is the visual programming developers are asking for. Developers need help with those problems and they resort to visuals to tackle them.
 github.com
github.com
> Supercompilation[^1^](https://doi.org/10.1145/5956.5957) is a program transformation technique that symbolically evaluates a given program, with run-time values as unknowns. In doing so, it discovers execution patterns of the original program and synthesizes them into standalone functions; the result of supercompilation is a more efficient residual program. In terms of transformational power, supercompilation subsumes both deforestation[^2^](https://doi.org/10.1016/0304-3975(90)90147-A) and partial evaluation[^3^](https://doi.org/10.1007/3-540-11980-9_13), and even exhibits certain capabilities of theorem proving. > > Mazeppa is a modern supercompiler intended to be a compilation target for call-by-value functional languages. Unlike previous supercompilers, Mazeppa 1) provides the full set of primitive data types, 2) supports manual control of function unfolding, 3) is fully transparent in terms of what decisions it takes during transformation, and 4) is designed with efficiency in mind from the very beginning. [Supercompilation explained on Stack Overflow](https://stackoverflow.com/a/10888771) Mazeppa example (https://github.com/mazeppa-dev/mazeppa/blob/master/examples/sum-squares/main.mz): > ```mazeppa > main(xs) := sum(mapSq(xs)); > > sum(xs) := match xs { > Nil() -> 0i32, > Cons(x, xs) -> +(x, sum(xs)) > }; > > mapSq(xs) := match xs { > Nil() -> Nil(), > Cons(x, xs) -> Cons(*(x, x), mapSq(xs)) > }; > ``` Mazeppa automatically translates the above program into the semantically-equivalent but more efficient: > ```mazeppa > main(xs) := f0(xs); > > f0(x0) := match x0 { > Cons(x1, x2) -> +(*(x1, x1), f0(x2)), > Nil() -> 0i32 > }; > ``` It also generates a graph to visualize and debug the transformation ([SVG if it doesn't load](https://github.com/mazeppa-dev/mazeppa/blob/master/media/sum-squares.svg)): > 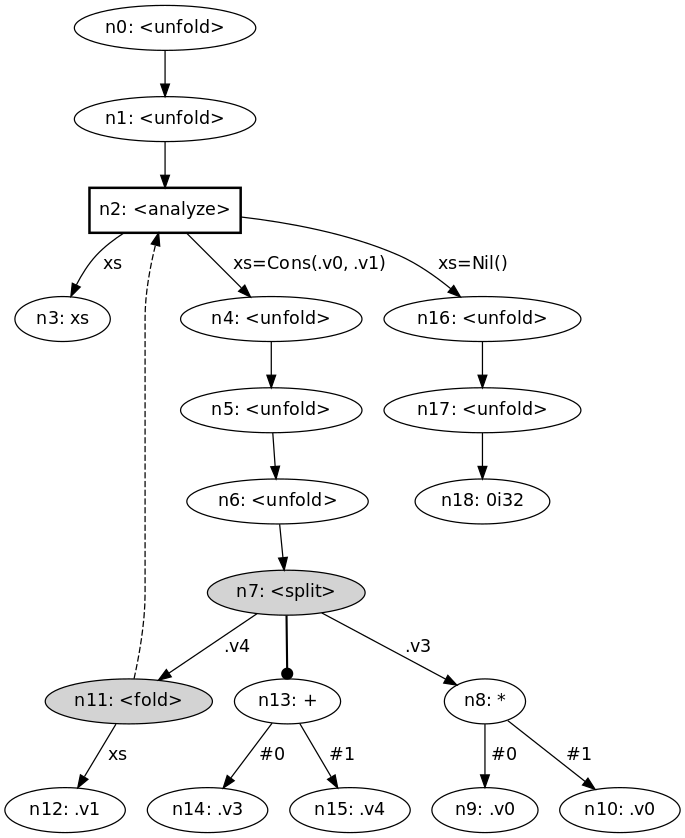 Mazeppa is written in [OCaml](https://ocaml.org/) and [can be used as an OCaml library](https://stackoverflow.com/a/10888771).
> Think Repl.it, but a simpler version for esoteric languages, with a visual debugger catered to each language, that runs in your browser. The linked example shows a Brainfuck "Hello world!" program. You can run it and visualize instructions executed in real time, the memory, and the output. You can pause/step, insert breakpoints, adjust the delay after each instruction, and enter user input. There's also syntax highlighting and checking. [All languages](https://esolangpark.vercel.app/)
Some features: - Ruby-like syntax, terse lambdas that look like regular control statements. - Everything is an object. - Integrated package manager. **Jaguar** is a small app that wirelessly connects to an [ESP32](https://en.wikipedia.org/wiki/ESP32) and can load and live-reload Toit programs. This is opposed to something like connecting the device via USB and re-installing the program every time you make a change. Example (https://github.com/toitlang/toit/blob/master/examples/wifi/scan.toit, see the GitHub link for syntax highlighting): > ```toit > // Copyright (C) 2022 Toitware ApS. > // Use of this source code is governed by a Zero-Clause BSD license that can > // be found in the examples/LICENSE file. > > // This example illustrates how to scan for WiFi access points. > > import net.wifi > > SCAN-CHANNELS := #[1, 2, 3, 4, 5, 6, 7] > > main: > access-points := wifi.scan > SCAN-CHANNELS > --period-per-channel-ms=120 > if access-points.size == 0: > print "Scan done, but no APs found" > return > > print """ > $(%-32s "SSID") $(%-18s "BSSID") \ > $(%-6s "RSSI") $(%-8s "Channel") \ > $(%-8s "Author")\n""" > > access-points.do: | ap/wifi.AccessPoint | > print """ > $(%-32s ap.ssid) $(%-18s ap.bssid-name) \ > $(%-6s ap.rssi) $(%-8s ap.channel) \ > $(%-8s ap.authmode-name)""" > ```
> [Scrapscript](https://scrapscript.org/) is a small, pure, functional, content-addressable, network-first programming language. > > ```scrapscript > fact 5 > . fact = > | 0 -> 1 > | n -> n * fact (n - 1) > ``` > > My [previous post](https://bernsteinbear.com/blog/scrapscript-baseline/) talked about the compiler that Chris and I built. This post is about some optimization tricks that we've added since. > > Pretty much all of these tricks are standard operating procedure for language runtimes (OCaml, MicroPython, Objective-C, Skybison, etc). We didn't invent them. > > They're also somewhat limited in scope; the goal was to be able to add as much as possible to the baseline compiler without making it or the runtime notably more complicated. A fully-featured optimizing compiler is coming soon™ but not ready yet.
 buttondown.email
buttondown.email
The blog explains how to solve the following problem using [Picat](http://picat-lang.org/) and [**planner programming**](https://www.hillelwayne.com/post/picat/), a form of [**logic programming**](https://en.wikipedia.org/wiki/Logic_programming): > Suppose that at the beginning there is a blank document, and a letter "a" is written in it. In the following steps, only the three functions of "select all", "copy" and "paste" can be used. > > Find the minimum number of steps to reach **at least** 100,000 a's (each of the three operations of "select all", "copy" and "paste" is counted as one step). If the target number is not specified, and I want to get **the exact amount** of "a"s, is there a general formula? \- [Math Stack Exchange](https://math.stackexchange.com/questions/4939319/how-many-steps-are-needed-to-turn-one-a-into-at-least-100-000-as-using-only)
 www.orionreed.com
www.orionreed.com
A programming model that is a graph, where code is written on the edges to add behavior and interactivity to the connected nodes. Video demo: >  [Live demo](https://orionreed.github.io/scoped-propagators/)
> This pattern [([multi-stage programming](https://en.wikipedia.org/wiki/Multi-stage_programming))], which I'll refer to as "biphasic programming," is characterized by languages and frameworks that enable identical syntax to express computations executed in two distinct phases or environments while maintaining consistent behavior (i.e., semantics) across phases. These phases typically differ temporally (when they run), spatially (where they run), or both.[](https://rybicki.io/blog/2024/06/30/biphasic-programming.html#fn:1) [An older (2017) page on multi-stage programming](https://okmij.org/ftp/meta-programming/index.html) [Winglang ("a programming language for the cloud"), the author's language](https://www.winglang.io/)
Abstract: > We present associated effects, a programming language feature that enables type classes to abstract over the effects of their function signatures, allowing each type class instance to specify its concrete effects. > > Associated effects significantly increase the flexibility and expressive power of a programming language that combines a type and effect system with type classes. In particular, associated effects allow us to (i) abstract over total and partial functions, where partial functions may throw exceptions, (ii) abstract over immutable data structures and mutable data structures that have heap effects, and (iii) implement adaptors that combine type classes with algebraic effects. > > We implement associated effects as an extension of the Flix programming language and refactor the Flix Standard Library to use associated effects, significantly increasing its flexibility and expressive power. Specifically, we add associated effects to 11 type classes, which enables us to add 28 new type class instances. See also: [the Flix programming language](https://flix.dev/)
 icfp24.sigplan.org
icfp24.sigplan.org
Abstract: > The *expression problem* describes how most types can easily be extended with new ways to *produce* the type or new ways to *consume* the type, but not both. When abstract syntax trees are defined as an algebraic data type, for example, they can easily be extended with new consumers, such as `print` or `eval`, but adding a new constructor requires the modification of all existing pattern matches. The expression problem is one way to elucidate the difference between functional or data-oriented programs (easily extendable by new consumers) and object-oriented programs (easily extendable by new producers). > This difference between programs which are extensible by new producers or new consumers also exists for dependently typed programming, but with one core difference: Dependently-typed programming almost exclusively follows the functional programming model and not the object-oriented model, which leaves an interesting space in the programming language landscape unexplored. > In this paper, we explore the field of dependently-typed object-oriented programming by *deriving it from first principles* using the principle of duality. That is, we do not extend an existing object-oriented formalism with dependent types in an ad-hoc fashion, but instead start from a familiar data-oriented language and derive its dual fragment by the systematic use of defunctionalization and refunctionalization > Our central contribution is a dependently typed calculus which contains two dual language fragments. We provide type- and semantics-preserving transformations between these two language fragments: defunctionalization and refunctionalization. We have implemented this language and these transformations and use this implementation to explain the various ways in which constructions in dependently typed programming can be explained as special instances of the general phenomenon of duality. Background: [Expression problem (wikipedia)](https://en.wikipedia.org/wiki/Expression_problem) [Defunctionalization (wikipedia)](https://en.wikipedia.org/wiki/Defunctionalization) [Codata in action, or how to connect Functional Programming and Object Oriented Programming (Javier Casas)](https://www.javiercasas.com/articles/codata-in-action)
> Several months ago I gave a talk at work about Hindley-Milner type inference. When I agreed to give the talk I didn't know much about the subject, so I learned about it. And now I'm writing about it, based on the contents of my talk but more fleshed out and hopefully better explained. > > I call this a reckless introduction, because my main source is [wikipedia](https://en.wikipedia.org/wiki/Hindley%E2%80%93Milner_type_system). A bunch of people on the internet have collectively attempted to synthesise a technical subject. I've read their synthesis, and now I'm trying to re-synthesise it, without particularly putting in the effort to check my own understanding. I'm not going to argue that this is a good idea. Let's just roll with it.
> In this post, I will talk about the first version of the Intermediate Representation I designed for *Kunai Static Analyzer*, this is a dalvik analysis library that I wrote as a project for my PhD, also as a way of learning about the Dalvik file format and improving my programming skills. [Kunai source (Github)](https://github.com/Fare9/KUNAI-static-analyzer) [Kunai paper](https://www.sciencedirect.com/science/article/pii/S2352711023000663) [Shuriken (Kunai successor)](https://github.com/Fare9/Shuriken-Analyzer/) [Dalvik is a discountinued VM for Android](https://source.android.com/docs/core/runtime/dalvik-bytecode)
Pre-Scheme is an interesting Scheme dialect which is being ported to modern systems. The language, why its being ported, and the porting effort are described in the linked post. > As described in the [Pre-Scheme paper](https://prescheme.org/papers/prescheme.pdf), the language offers a unique combination of features: > > - Scheme syntax, with full support for macros, and a compatibility library to run Pre-Scheme code in a Scheme interpreter. The compiler is also implemented in Scheme, enabling both interactive development and compile-time evaluation. > - A static type system based on Hindley/Milner type reconstruction, as used in the ML family of languages (eg. Standard ML, OCaml, Haskell). Pre-Scheme supports parametric polymorphism, and has nascent support for algebraic data types and pattern matching, which are recently gaining popularity in mainstream languages. > - An optimizing compiler targeting C, allowing for efficient native code generation and portable low-level machine access. C remains the common interface language for operating system facilities, and compatibility at this level is essential for modern systems languages. > > Due to the restrictions of static typing and the C runtime model, Pre-Scheme does not (currently) support many of Scheme's high-level features, such as garbage collection, universal tail-call optimization, heap-allocated runtime closures, first-class continuations, runtime type checks, heterogenous lists, and the full numeric tower. Even with these limitations, Pre-Scheme enables a programming style that is familiar to Scheme programmers and more expressive than writing directly in C. Ironically, Pre-Scheme's original purpose was to implement the interpreter for another Scheme dialect, [Scheme 48](https://www.s48.org/) ([Wikipedia](https://en.wikipedia.org/wiki/Scheme_48)). But the lower-level Pre-Scheme is now getting its own attention, in part due to the popularity of Rust and Zig. Pre-Scheme has the portability and speed of C (or at least close to it), but like Rust and Haskell it also has a static type system with ADTs and parametric polymorphism; and being a LISP dialect, like most other dialects it has powerful meta-programming and a REPL.
[GitHub](https://github.com/Eliah-Lakhin/lady-deirdre) From README: > Lady Deirdre is a framework for incremental programming language compilers, interpreters, and source code analyzers. > > This framework helps you develop a hybrid program that acts as a language compiler or interpreter and as a language server for a code editor's language extension. It offers the necessary components to create an in-memory representation of language files, including the source code, their lexis and syntax, and the semantic model of the entire codebase. These components are specifically designed to keep the in-memory representation in sync with file changes as the codebase continuously evolves in real time. > ### Key Features > - Parser Generator Using Macros. > - Hand-Written Parsers. > - Error Resilience. > - Semantics Analysis Framework. > - Incremental Compilation. > - Parallel Computations. > - Web-Assembly Compatibility. > - Source Code Formatters. > - Annotated Snippets. > - Self-Sufficient API.
 github.com
github.com
Abstract from the [ICFP 2024 paper](https://andraskovacs.github.io/pdfs/2ltt_icfp24.pdf): > Many abstraction tools in functional programming rely heavily on general-purpose compiler optimization\ to achieve adequate performance. For example, monadic binding is a higher-order function which yields\ runtime closures in the absence of sufficient compile-time inlining and beta-reductions, thereby significantly\ degrading performance. In current systems such as the Glasgow Haskell Compiler, there is no strong guarantee\ that general-purpose optimization can eliminate abstraction overheads, and users only have indirect and\ fragile control over code generation through inlining directives and compiler options. We propose a two-stage\ language to simultaneously get strong guarantees about code generation and strong abstraction features. The\ object language is a simply-typed first-order language which can be compiled without runtime closures. The\ compile-time language is a dependent type theory. The two are integrated in a two-level type theory.\ We demonstrate two applications of the system. First, we develop monads and monad transformers. Here,\ abstraction overheads are eliminated by staging and we can reuse almost all definitions from the existing\ Haskell ecosystem. Second, we develop pull-based stream fusion. Here we make essential use of dependent\ types to give a concise definition of a concatMap operation with guaranteed fusion. We provide an Agda\ implementation and a typed Template Haskell implementation of these developments. The repo also contains demo implementations in Agda and Haskell), and older papers/implementations/videos.
F is written in [K](http://www.math.bas.bg/bantchev/place/k.html), another small language. In fact, the entire implementation is in one file: <http://www.nsl.com/k/f/f.k>. Example program (defines factorial and computes `fac(6)`, from <http://www.nsl.com/k/f/f/fac.f>): > ```f > [[1=][][dup!pred!fac!*]cond!]fac > ``` The main site, ["no stinking loops"](http://www.nsl.com/), is full of links including to other languages (scroll down) and resources on K. Although many are broken 🙁.
armchair_progamer 3 months ago • 100%
armchair_progamer 4 months ago • 100%
Author's comment on lobste.rs:
Yes it’s embeddable. There’s a C ABI compatible API similar to what lua provides.
armchair_progamer 4 months ago • 91%
C++’s mascot is an obese sick rat with a missing foot*, because it has 1000+ line compiler errors (the stress makes you overeat and damages your immune system) and footguns.
EDIT: Source (I didn't make up the C++ part)


armchair_progamer 4 months ago • 100%
I could understand method = associated function whose first parameter is named self, so it can be called like self.foo(…). This would mean functions like Vec::new aren’t methods. But the author’s requirement also excludes functions that take generic arguments like Extend::extend.
However, even the above definition gives old terminology new meaning. In traditionally OOP languages, all functions in a class are considered methods, those only callable from an instance are “instance methods”, while the others are “static methods”. So translating OOP terminology into Rust, all associated functions are still considered methods, and those with/without method call syntax are instance/static methods.
Unfortunately I think that some people misuse “method” to only refer to “instance method”, even in the OOP languages, so to be 100% unambiguous the terms have to be:
- Associated function: function in an
implblock. - Static method: associated function whose first argument isn’t
self(even if it takesSelfunder a different name, likeBox::leak). - Instance method: associated function whose first argument is
self, so it can be called likeself.foo(…). - Object-safe method: a method callable from a trait object.
armchair_progamer 5 months ago • 100%
Java the language, in human form.
armchair_progamer 5 months ago • 100%
I find writing the parser by hand (recursive descent) to be easiest. Sometimes I use a lexer generator, or if there isn’t a good one (idk for Scheme), write the lexer by hand as well. Define a few helper functions and macros to remove most of the boilerplate (you really benefit from Scheme here), and you almost end up writing the rules out directly.
Yes, you need to manually implement choice and figure out what/when to lookahead. Yes, the final parser won’t be as readable as a BNF specification. But I find writing a hand-rolled parser generator for most grammars, even with the manual choice and lookahead, is surprisingly easy and fast.
The problem with parser generators is that, when they work they work well, but when they don’t work (fail to generate, the generated parser tries to parse the wrong node, the generated parser is very inefficient) it can be really hard to figure out why. A hand-rolled parser is much easier to debug, so when your grammar inevitably has problems, it ends up taking less time in total to go from spec to working hand-rolled vs. spec to working parser-generator-generated.
The hand-rolled rules may look something like (with user-defined macros and functions define-parse, parse, peek, next, and some simple rules like con-id and name-id as individual tokens):
; pattern ::= [ con-id ] factor "begin" expr-list "end"
(define-parse pattern
(mk-pattern
(if (con-id? (peek)) (next))
(parse factor)
(do (parse “begin”) (parse expr-list) (parse “end”))))
; factor ::= name-id
; | symbol-literal
; | long-name-id
; | numeric-literal
; | text-literal
; | list-literal
; | function-lambda
; | tacit-arg
; | '(' expr ')'
(define-parse factor
(case (peek)
[name-id? (if (= “.” (peek2)) (mk-long-name-id …) (next))]
[literal? (next)]
…))
Since you’re using Scheme, you can almost certainly optimize the above to reduce even more boilerplate.
Regarding LLMs: if you start to write the parser with the EBNF comments above each rule like above, you can paste the EBNF in and Copilot will generate rules for you. Alternatively, you can feed a couple EBNF/code examples to ChatGPT and ask it to generate more.
In both cases the AI will probably make mistakes on tricky cases, but that’s practically inevitable. An LLM implemented in an error-proof code synthesis engine would be a breakthrough; and while there are techniques like fine-tuning, I suspect they wouldn’t improve the accuracy much, and certainly would amount to more effort in total (in fact most LLM “applications” are just a custom prompt on plain ChatGPT or another baseline model).
armchair_progamer 5 months ago • 100%

armchair_progamer 5 months ago • 100%
My general take:
A codebase with scalable architecture is one that stays malleable even when it grows large and the people working on it change. At least relative to a codebase without scalable architecture, which devolves into "spaghetti code", where nobody knows what the code does or where the behaviors are implemented, and small changes break seemingly-unrelated things.
Programming language isn't the sole determinant of a codebase's scalability, especially if the language has all the general-purpose features one would expect nowadays (e.g. Java, C++, Haskell, Rust, TypeScript). But it's a major contributor. A "non-scalable" language makes spaghetti design decisions too easy and scalable design decisions overly convoluted and verbose. A scalable language does the opposite, nudging developers towards building scalable software automatically, at least relative to a "non-scalable" language and when the software already has a scalable foundation.
armchair_progamer 5 months ago • 96%
public class AbstractBeanVisitorStrategyFactoryBuilderIteratorAdapterProviderObserverGeneratorDecorator {
// boilerplate goes here
}
armchair_progamer 6 months ago • 100%

armchair_progamer 6 months ago • 100%
“You're going into Orbit, you stupid mutt.”
armchair_progamer 6 months ago • 100%
I believe the answer is yes, except that we’re talking about languages with currying, and those can’t represent a zero argument function without the “computation” kind (remember: all functions are Arg -> Ret, and a multi-argument function is just Arg1 -> (Arg2 -> Ret)). In the linked article, all functions are in fact “computations” (the two variants of CompType are Thunk ValType and Fun ValType CompType). The author also describes computations as “a way to add side-effects to values”, and the equivalent in an imperative language to “a value which produces side-effects when read” is either a zero-argument function (getXYZ()), or a “getter” which is just syntax sugar for a zero-argument function.
The other reason may be that it’s easier in an IR to represent computations as intrinsic types vs. zero-argument closures. Except if all functions are computations, then your “computation” type is already your closure type. So the difference is again only if you’re writing an IR for a language with currying: without CBPV you could just represent closures as things that take one argument, but CBPV permits zero-argument closures.
armchair_progamer 6 months ago • 100%
Go as a backend language isn’t super unusual, there’s at least one other project (https://borgo-lang.github.io) which chosen it. And there are many languages which compile to JavaScript or C, but Go strikes a balance between being faster than JavaScript but having memory management vs. C.
I don’t think panics revealing the Go backend are much of an issue, because true “panics” that aren’t handled by the language itself are always bad. If you compile to LLVM, you must implement your own debug symbols to get nice-looking stack traces and line-by-line debugging like C and Rust, otherwise debugging is impossible and crashes show you raw assembly. Even in Java or JavaScript, core dumps are hard to debug, ugly, and leak internal details; the reason these languages have nice exceptions, is because they implement exceptions and detect errors on their own before they become “panics”, so that when a program crashes in java (like tries to dereference null) it doesn’t crash the JVM. Golang’s backtrace will probably be much nicer than the default of C or LLVM, and you may be able to implement a system like Java which catches most errors and gives your own stacktrace beforehand.
Elm’s kernel controversy is also something completely different. The problem with Elm is that the language maintainers explicitly prevented people from writing FFI to/from JavaScript except in the maintainers’ own packages, after allowing this feature for a while, so many old packages broke and were unfixable. And there were more issues: the language itself was very limited (meaning JS FFI was essential) and the maintainers’ responses were concerning (see “Why I’m leaving Elm”). Even Rust has features that are only accessible to the standard library and compiler (“nightly”), but they have a mechanism to let you use them if you really want, and none of them are essential like Elm-to-JS FFI, so most people don’t care. Basically, as long as you don’t become very popular and make a massively inconvenient, backwards-incompatible change for purely design reasons, you won’t have this issue: it’s not even “you have to implement Go FFI”, not even “if you do implement Go FFI, don’t restrict it to your own code”, it’s “don’t implement Go FFI and allow it everywhere, become very popular, then suddenly restrict it to your own code with no decent alternatives”.
armchair_progamer 7 months ago • 100%
https://github.com/cell-lang/example-online-forum
https://github.com/cell-lang/example-imdb
A more complex example, the compiler itself is written in Cell: https://github.com/cell-lang/compiler/tree/master
The getting started page has download links for the code generators (C++, Java, and C#) and setup instructions.
armchair_progamer 7 months ago • 100%
Another resource is PLDB which is more of an index: it has many more languages, but less detail and curation.
armchair_progamer 7 months ago • 100%
You probably need to annotate recursive function return values. I know in some languages like Swift and Kotlin, at least in some cases this is required; and other languages have you annotate every function’s return value (or at least, every function which isn’t a lambda expression). So IMO it’s not even as much of a drawback as the other two.
armchair_progamer 8 months ago • 50%
I would just transmit the program as source (literally send y = mx + b) instead of trying to serialize it into JSON or anything. You'll have to write a parser anyways, printing is very easy, and sending as source minimizes the points of failure.
Your idea isn't uncommon, but there's no standard set of operations because it varies depending on what you code needs to achieve. For instance, your code needs to make plots, other programs send code for plugins, deployment steps, or video game enemies.
There is a type of language for what you're trying to achieve, the embedded scripting language ("embedded" in that it's easy to interpret and add constants/hooks from a larger program). And the most well-known and well-supported embedded scripting language is Lua. Alternatively, assuming you're only using basic math operators, I recommend you just make your own tiny language, it may actually be easier to do so than integrate Lua.
armchair_progamer 10 months ago • 100%
No, that would probably be shuai.fu@monash.edu. I just saw it on HN.
armchair_progamer 10 months ago • 100%
Yes. Unfortunately I’m not very familiar with GHC and HLS internals.
What I do know is that when GHC is invoked with a certain flag, as it compiles each Haskell file, it generates a .hie file with intermediate data which can be used by IDEs. So HLS (and maybe JetBrains Haskell) works by invoking GHC to parse and type-check the active haskell file, and then queries the .hie file to get diagnostics, symbol lookups, and completions. There’s also a program called hiedb which can query .hie files on the command line.
Rust’s language server is completely different (salsa.rs). The common detail is that both of them have LLVM IR, but also higher-level IRs, and the compiler passes information in the higher-level IRs to IDEs for completions/lookups/diagnostics/etc. (in Haskell via the generated .hie files)
armchair_progamer 10 months ago • 100%
The main drawback is being a new incomplete language. No solid IDE support, huge online resources, training data for LLMs; and you have a not-tiny chance of the compiler crashing or producing the wrong output.
IDE-friendliness and most of the other features, I don’t think there are any major flaws. The main drawback with these is implementation complexity, possibly slower compile time (and maybe runtime if this IR prevents optimizations). There are also unknown drawbacks of doing new and experimental things. Maybe they have the right idea but will take the wrong approach, e.g. create an IR which is IDE-friendly but has issues in the design, which a different IDE-friendly IR would not.
Some of these features and ideas have been at least partly tried before. The JVM bytecode is very readable. LLVM IR is not, but most languages (e.g. Rust, Haskell) have some higher intermediate-representation which is and the IDE does static analysis off of that. And some of the other features (ADTs, functor-libs, blocks) are already common in other languages, especially newer ones.
But there are some features like typed-strings and invariants, which to me seem immediately useful but I don’t really see them in other languages. Ultimately I don’t think I can really speak to the language’s usefulness or flaws before they are further in development, but I am optimistic if they keep making progress.
armchair_progamer 10 months ago • 100%
Whoever makes the Advent of Code problems should test all them on GPT4 / other LLMs and try to make it so the AI can't solve them.
armchair_progamer 11 months ago • 100%
It's funny because, I'm probably the minority, but I strongly prefer JetBrains IDEs.
Which ironically are much more "walled gardens": closed-source and subscription-based, with only a limited subset of parts and plugins open-source. But JetBrains has a good track record of not enshittifying and, because you actually pay for their product, they can make a profitable business off not doing so.
armchair_progamer 11 months ago • 100%
Also in case you missed, these are the most recent proceedings for (AFAIK) all of the major PL conferences:
- ICFP 2023: https://dl.acm.org/toc/pacmpl/2023/7/ICFP
- PLDI 2023: https://dl.acm.org/toc/pacmpl/2023/7/PLDI
- POPL 2023: https://dl.acm.org/toc/pacmpl/2023/7/POPL
- OOPSLA 2022: https://dl.acm.org/toc/pacmpl/2022/6/OOPSLA1
- ECOOP 2022: https://drops.dagstuhl.de/opus/portals/lipics/index.php?semnr=16234
And they have ones for prior years
armchair_progamer 11 months ago • 100%
This speaks personally to me: I work on an alternate compiler for a language whose specification is "whatever the main interpreter does" and this leads to some weird, unwieldy semantic edge-cases.
armchair_progamer 11 months ago • 100%
Rust isn't good for fast iteration (Python with GPU-accelarated is still the winner here). Mojo could indeed turn out to be the next big thing for AI programming. But there are a few issues:
-
The #1 thing IMO, Modular still hasn't released the source for the compiler. Nobody uses a programming language without an open-source compiler! (Except MATLAB/Mathematica but that has its own controversies and issues. Seriously, what's the next highest-ranking language on Stack Overflow rankings with only closed-source compilers/interpreters? Is there even any?)
- Even if Mojo is successful, the VC funding combined with the compiler being closed-source mean that the developers may try to extract money from the users. e.g., by never releasing the source and charging people for using Mojo or for extra features and optimizations. Because VCs don't just give money away. There's a reason nearly every popular language is open-source, and it's not just the goodness of people's hearts...not just individuals, but big companies don't want to pay to use a language, nor risk having to pay when their supplier changes the terms.
-
Modular/Mojo has lots of bold claims ("programming language for all of AI", "the usability of Python with the performance of C") without much to show for them. Yes, Mojo got 35,000 speedup from Python on a small benchmark; but writing a prototype language which achieves massive speedups without compromising readability on small benchmark, is considerably easier than doing so for a large, real-world ML program. It's not that I expect Mojo to already be used in real-world programs, I don't, I get that it's in the early-stage. It's that Modular really shouldn't be calling it the "programming language for all of AI" when so far, none of today's AI is written in Mojo.
- What makes the Mojo developers think they can make something that others can't? The field of programming languages is dominated by very smart, very talented people. So many, it's hard to imagine Mojo developing anything which others won't be able to replicate in a few months of dedicated coding. And if Mojo doesn't open-source their compiler, those others will do so, both with funding from competing companies and universities and in their spare time.
With all that being said, I have decent hopes for Mojo. I can imagine that the bold claims and toy benchmarks are just a way to get VC funding, and the actual developers have realistic goals and expectations. And I do predict that Mojo will succeed in its own niche, as a language augmenting Python to add high-performance computing; and since it's just augmenting Python, it probably will do this within only one or two years, using Python's decades of development and tooling to be something which can be used in production. What I don't expect, is for it to be truly groundbreaking and above the competition in a way that the hype sometimes paints it as.
And if they do succeed, they need to open-source the compiler, or they will have some competitor which I will be supporting.
armchair_progamer 1 year ago • 95%
I’m not involved in piracy/DRM/gamedev but I really doubt they’ll track cracked installs and if they do, actually get indie devs to pay.
Because what’s stopping one person from “cracking” a game, then “installing” it 1,000,000 times? Whatever metric they use to track installs has to prevent abuse like this, or you’re giving random devs (of games that aren’t even popular) stupidly high bills.
When devs see more installs than purchases, they’ll dispute and claim Unity’s numbers are artificially inflated. Which is a big challenge for Unity’s massive legal team, because in the above scenario they really are. Even if Unity successfully defends the extra installs in court, it would be terrible publicity to say “well, if someone manages to install your game 1,000 times without buying it 1,000 times you’re still responsible”. Whatever negative publicity Unity already has for merely charging for installs pales in comparison, and this would actually get most devs to stop using Unity, because nobody will risk going into debt or unexpectedly losing a huge chunk of revenue for a game engine.
So, the only reasonable metric Unity has to track installs is whatever metric is used to track purchases, because if someone purchases the game 1,000,000 times and installs it, no issue, good for the dev. I just don’t see any other way which prevents easy abuse; even if it’s tied to the DRM, if there’s a way to crack the DRM but not remove the install counter, some troll is going to do it and fake absurd amounts of extra installs.
armchair_progamer 1 year ago • 100%
Yeah this one's a miss on my end. I saw "ad-hoc polymorphism is UNSAFE?" and well, it does a better job reinforcing that ad-hoc polymorphism is not unsafe.
Author should have wrote a piece "how even type-safe programs can fail" and used his example to show that. Because what this really shows is that type-safety doesn't prevent programs with the correct types but bad semantics. But that's not ad-hoc polymorphism; it can happen anywhere (sans ultra-specific types) including even the author's workaround if he used Vec<Vec instead
armchair_progamer 1 year ago • 100%
Plus the issue remains if the author replaced Vec with Vec of Vec instead of Option of Vec, or if iter().count() meant something completely different than “count # of iterated elements” (both pointed out in HN comments).
armchair_progamer 1 year ago • 100%
Usually when I buy bigger packs of salmon, the amount varies and the only thing roughly consistent is the weight. So if they decreased the weight, you might either get 2 bigger fillets or 3 smaller fillets depending on the package
armchair_progamer 1 year ago • 100%
You can see here for info on VS Code's DAP integration, and here for neovim. I think the IDE connects to the server when it loads a file of the server's registered type. However in theory you can always have the server start the IDE (or connect to a running IDE process) and then make the IDE connect (by calling a function or opening a file and triggering whatever else is necessary).
armchair_progamer 1 year ago • 100%
Can they live in the same process (which is their host application)
I believe so, since you can host a client and server in the same process. You could use threads, co-routines, or polling to get the server to listen while the interpreter is running and vice versa
armchair_progamer 1 year ago • 100%
Not 100% clear, but:
A language server is an HTTP server which implements the LSP protocol. So you can run an embedded interpreter with access to sockets, then run code on the interpreter which starts the language server. Clients (IDEs) would connect to this server and send requests on the files being edited, which could be in the same language as the interpreter runs.
Although the interpreter runs code, it doesn't handle editing code. The server could use eval and reflection to process LSP requests. For instance, editor requests available symbols -> interpreter sources the file (taking care to not run side effects, just load definitions) -> interpreter uses reflection to get available symbols -> interpreter responds to the editor.
However, the language server needs to read definitions from the file quickly and doing so shouldn't cause any side effects, so interpreting the file may not actually be very beneficial. Typically a language server would be written in a language like C++ or Rust, which parses the source code and then uses special queries to extract information very quickly. See for example rust-analyzer and their blog posts, most recently on their incremental computation engine. Also, each feature and diagnostic listed in the manual has a link to the source code where said feature is implemented (ex: annotations).
What I do think is a good idea is having the interpreter implement the Debug Adapter Protocol. The interpreter, when run with a special flag, would start a debug server which IDEs can connect to. Then the IDE would send requests to evaluate specific programs and source code (see the DAP specification) as well as requests to add breakpoints etc.; since it's already built to interpret code, the interpreter is already partway there to handling these requests.
armchair_progamer 1 year ago • 100%
The important parts IMO (emphasis mine):
Our results show that both systems indeed reach performance close to Node.js/V8. Looking at interpreter- only performance, our AST interpreters are on par with, or even slightly faster than their bytecode counterparts. After just-in-time compilation, the results are roughly on par. This means bytecode interpreters do not have their widely assumed performance advantage. However, we can confirm that bytecodes are more compact in memory than ASTs, which becomes relevant for larger applications. However, for smaller applications, we noticed that bytecode interpreters allocate more memory because boxing avoidance is not as applicable, and because the bytecode interpreter structure requires memory, e.g., for a reified stack.
Our results show AST interpreters to be competitive on top of meta-compilation systems. Together with possible engineering benefits, they should thus not be discounted so easily in favor of bytecode interpreters.
armchair_progamer 1 year ago • 100%
If we could somehow perform LR(0) everywhere that it was good enough, and switch to a more powerful method for those parts of the grammar where strictly necessary, then we should see a nice compromise of speed and size while achieving the full recognition power of the stronger method.
In practice, I find hand-rolled parsers are usually the best and easiest to write. Hand-rolleds are also usually LR0 when possible, state and "peeked" tokens are stored in local variables or fields in the Parser class.
armchair_progamer 1 year ago • 100%
Multiple ways you can do this. Most of these should also extend to multiple arguments, and although the constant is promoted to type level, you can pass it around nested functions as a type parameter.
With generics
In Java (personally I think this approach is best way to implement your specific example; also Kotlin, C#, and some others are similar):
interface HashAlgo<Options> {
String hash(String password, Options options);
}
class Bcrypt implements HashAlgo<BcryptOptions> { ... }
class Argon2 implements HashAlgo<Argon2Options> { ... }
record BcryptOptions { ... }
record Argon2Options { ... }
In Haskell without GADTs (also Rust is similar):
class HashAlgo opts where
hash :: String -> opts -> String
data BcryptOptions = BcryptOptions { ... }
data Argon2Options = Argon2Options { ... }
instance HashAlgo BcryptOptions where
hash password BcryptOptions { .. } = ...
instance HashAlgo Argon2Options where
hash password Argon2Options { .. } = ...
In C (with _Generic):
typedef struct { ... } bcrypt_options;
typedef struct { ... } argon2_options;
char* hash_bcrypt(const char* password, bcrypt_options options) { ... }
char* hash_argon2(const char* password, argon2_options options) { ... }
#define hash(password, options) _Generic((options), bcrypt_options: hash_bcrypt, argon2_options: hash_argon2)(password, options)
In TypeScript, inverting which type is parameterized (see this StackOverflow question for another TypeScript approach):
type HashAlgo = 'bcrypt' | 'argon2'
type HashOptions<H> = H extends 'bcrypt' ? BcryptOptions : H extends 'argon2' ? ArgonOptions : never
function hash<H>(password: string, algorithm: H, options: HashOptions<H>): string { ... }
With constant generics or full dependent types
This way is a bit more straightforward but also way more complicated for the compiler, and most languages don't have these features or they're very experimental. Dependent types are useful when your constant is non-trivial to compute and you can't even compute it fully, like vectors with their length as a type parameter and append guarantees the return vector's length is the sum. In that case generics aren't enough. Constant generics aren't full dependent types but let you do things like the vector-sum example.
In Haskell with GADTs AKA Generic Algebraic Data types (also works in Idris, Agda, and other Haskell-likes; you can simulate in Rust using GATs AKA Generic Associated Types, but it's much uglier):
data BcryptOptions = BcryptOptions { ... }
data Argon2Options = Argon2Options { ... }
data Algorithm opts where
Bcrypt :: Algorithm BcryptOptions
Argon2 :: Algorithm Argon2Options
hash :: String -> Algorithm opts -> opts -> String
hash password algo opts =
case algo of
| Bcrypt -> ... -- opts is inferred to be BcryptOptions here
| Argon2 -> ... -- opts is inferred to be Argon2Options here
In Coq (also flipping the parameterized types again):
Inductive algorithm : Set := bcrypt | argon2.
Inductive algorithm_options (A: algorithm) : Set := bcrypt_options : ... -> algorithm_options bcrypt | argon2_options : ... -> algorithm_options argon2.
Fixpoint hash (password : string) (algo : algorithm) (opts : algorithm_options also) : string := ... .